To be quick - for recent idea I need to segment audio file, perfectly after one speaker finish his sentence and second speaker start talking. Also I need to detect number of unique speakers in audio.
There are plenty of libraries out there from lot's of Universities or proffessor or Phd's. All of them are commonly using same ideas from speech recognition topic. I won't be digging to them in this post. Unfortunately none of them is working perfectly for this task.
So I got my hands dirty in audio by using python and I found out I need some utility to help me with cutting / plotting audio files so I can progress faster. I created some utility class for doing it using scipy matplotlib and numpy. There is not much code now but you can use it freely if you want to:
- open file and convert it to mono
- cut seconds from audio file
- get seconds of audio file
- process audio file using custom method
- save file wrapper over scipy.io.wav
- spectrogram with matplotlib.specgram
You can try it just by typing:
python audio.py test.wav
But as I wrote before you need scipy, matplotlib and numpy to use it.
If and when you manage to execute it against your wav file without errors you should see spectrogram chart with wav file plot. On X axis it would be number of seconds. On Y probably signal amplitude but I could be wrong.
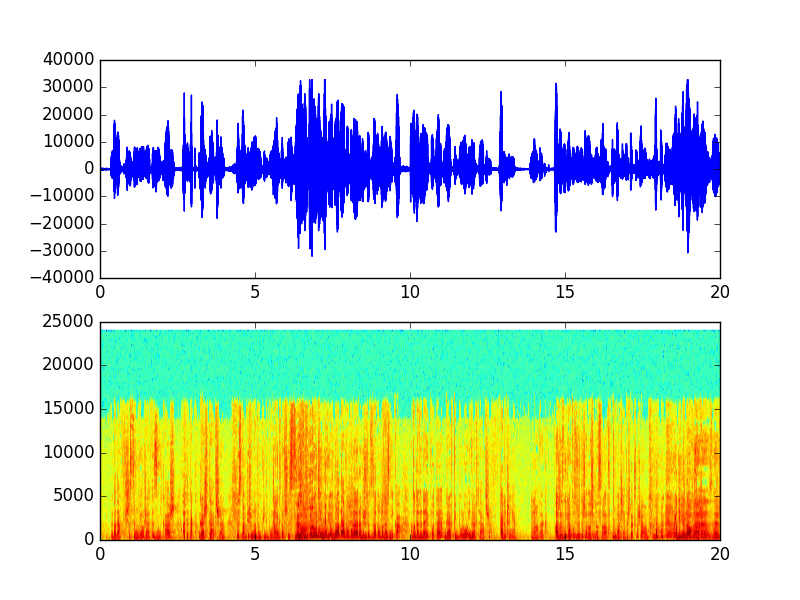
If you look to the end of the code it is simply one liner.
spectrogram(*to_mono(sys.argv[1]))[0].show()
I will try to update library and also this post with list of features as I need some more methods. Also maybe I will write something more about my audio segmentation and speaker diarisation struggles.
I embedded github gist below so it will be easier to copy it.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
BSD 3-Clause License
Copyright (c) 2017, Michal Szczepanski
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
* Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
"""
import sys
import scipy.io.wavfile as wav
import numpy as np
import matplotlib.pyplot as plt
""" PROCESS DATA """
def to_mono(fname, channel=0):
"""
Opens wav file and returns it as mono file if stereo
:param fname: file name
:param channel: channel index - default 0
:return: tuple of frequency and data numpy array
"""
(freq, sig) = wav.read(fname)
if sig.ndim == 2:
return (sig[:,channel], freq)
return (sig, freq)
def cut(data, freq, start, end):
"""
Cut track array from start (in seconds) to end (in seconds)
or till end of track if end second is bigger then track length
:param track: wav audio data
:param start: start (in seconds)
:param end: end (in seconds)
:param freq: frequency of audio data
:return:
"""
end = int(end*freq)
if end > len(data):
return data[int(start*freq):]
return data[int(start*freq):end]
def seconds(data, freq):
"""
Returns number of seconds from track data based on frequency
:param track: wav audio data
:param freq: frequency of audio data
:return: number of seconds
"""
return len(data)/freq
def process(data, callback=None):
"""
Can modify audio signal with callback function applied to every frame of data
or simply return copy of the track if callback is None
:param data: wav audio data
:param callback: method to be invoked every step of track
:return: copy of track with applied modifications
"""
if not callback:
def callback(t):
return t
output = np.empty(shape=[len(data)], dtype=np.int16)
for i in xrange(0, len(data)):
output.put(i, callback(data[i]))
return output
""" FILE UTILS """
def save(filename, data, freq):
"""
Wrapper for scipy.io.wavfile write method
:param filename: name of wav file
:param freq: frequency of audio data
:param data: wav audio data
"""
wav.write(filename=filename, rate=freq, data=data)
""" DRAW DATA """
def spectrogram(data, freq, NFFT=256, noverlap=128, mode='psd', sides='default'):
"""
Draws spectrogram of audio file with audio file data using matplotlib specgram method
minimal arguments are audio data and frequency
:param data: wav audio data
:param freq: see matplotlib.specgram Fs - here frequency of audio data
:param NFFT: see matplotlib.specgram
:param noverlap: see.matplotlib.specgram
:param mode: see matplotlib.specgram
:param sides: see matplotlib.specgram
:return: see matplotlib.specgram - first parameter is matplotlib.pyplot
"""
sec = seconds(data, freq)
xtick = np.linspace(0, sec, num=len(data))
ax1 = plt.subplot(211)
plt.plot(xtick, data)
plt.subplot(212, sharex=ax1)
spec, f, t, i = plt.specgram(data, NFFT=NFFT, Fs=freq, noverlap=noverlap, mode=mode, sides=sides)
return (plt, spec, f, t, i)
if __name__ == '__main__':
print("Will draw spectrogram of given audio file ex. python audio.py test.wav")
if len(sys.argv) == 2:
spectrogram(*to_mono(sys.argv[1]))[0].show()