For side project I am working on I have a problem with long running tasks that blocks requests inside http server for 1 to 30 seconds depending on the task.
I decided to use flask for this project since it have nice blueprint feature that each could be transformed into microservice when necessary.
To scale my http servers and distribute workload among other machines I need some broker / publish subscribe / some sort of queue.
Since all my backend stack is in python for rapid development I decided to use celery with redis.
Redis because I can also use it as session store and leverage as cache layer and I don't need to introduce another element or language if I try ex. RabbitMQ
I also decided to store my task results in postgresql since I like sql database to store important data and I can use one of the nice plugins for flask - Flask SQLAlchemy
And also I can later convert my database to some cloud solution like this great cockroachdb created by former google employees without scarifying code since it's using postgres driver.
Since I wrote about almost whole stack but one I want to mention last part which is haproxy that will be my load balancer of choice.
I will draw whole part in great opensource UML plugin/standalone tool umlet. But please forgive me uml champions for my inconvenient diagram.
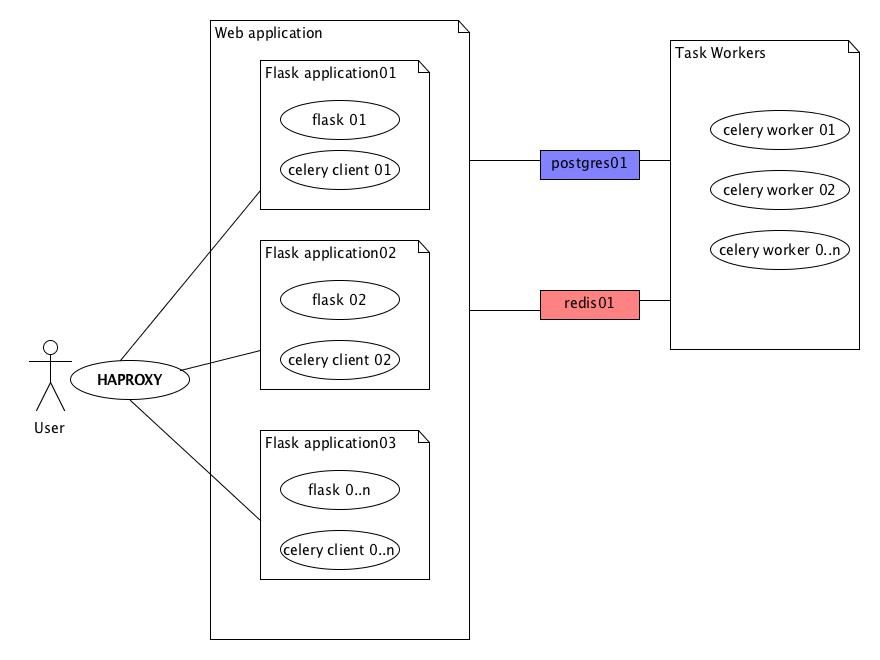 Ok so now to the celery itself since it's healthy to eat it.
First I want all my workers be classes so I can define some internal methods if I want to.
Obviously I am not building distributed calculator from examples but actual application ( I hope so )
So instead of this :
Ok so now to the celery itself since it's healthy to eat it.
First I want all my workers be classes so I can define some internal methods if I want to.
Obviously I am not building distributed calculator from examples but actual application ( I hope so )
So instead of this :
@app.task
def add(a, b):
return a+b
my actual task looks like this:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import celery
class Hello(celery.Task):
serializer = 'json'
name = 'tasks.hello'
def run(self, *args, **kwargs):
return 'hello {0}'.format(*args)
and it's located in some file called test.py in package foo
my celery task runner runner.py on the other hand besides some checking if database for results exist looks like that:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import celery
import foo.test
app = celery.Celery("hello")
app.config_from_object('foo.conf')
app.tasks.register(foo.test.Hello())
let me also paste here details from my config file named conf located in foo package:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
task_serializer = 'json'
result_serializer = 'json'
accept_content = ['json']
timezone = 'Europe/London'
enable_utc = True
broker_url = 'redis://localhost:6379/1'
result_backend = 'db+sqlite:///result.db'
with that in place I can start my worker from command line using:
celery --app=runner worker --loglevel=info
it would result with nice log output where I can check that my task test.hello exists
-------------- celery@siema v4.1.0 (latentcall)
---- **** -----
--- * *** * -- bla-bla-bla-64bit 2018-03-25 22:08:17
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: hello:0x10e81b080
- ** ---------- .> transport: redis://localhost:6379/1
- ** ---------- .> results: sqlite:///result.db
- *** --- * --- .> concurrency: 4 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
[tasks]
. test.hello
[2018-03-25 22:08:18,403: INFO/MainProcess] Connected to redis://localhost:6379/1
[2018-03-25 22:08:18,424: INFO/MainProcess] mingle: searching for neighbors
[2018-03-25 22:08:19,497: INFO/MainProcess] mingle: all alone
[2018-03-25 22:08:19,518: INFO/MainProcess] celery@siema ready.
Now if I would like to use database other then sqlite I need to check if connection and database exists. See documentation for details.
Ok so now I can run my test_celery.py
located in test directory
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import celery
import foo.test
app = celery.Celery('hello')
app.config_from_object('foo.conf')
def hello_test():
t = foo.test.Hello()
result = t.delay('siema')
res = result.get(timeout=1)
print(res)
if __name__ == '__main__':
hello_test()
from command line:
PYTHONPATH=./ python3 test/test_celery.py
and get response:
hello siema
on the other hand in celery console I got:
[2018-03-25 22:16:39,838: INFO/MainProcess] Received task: test.hello[c49e0bac-5587-48da-8c01-72ae4a53f93e]
[2018-03-25 22:16:39,974: INFO/ForkPoolWorker-2] Task test.hello[c49e0bac-5587-48da-8c01-72ae4a53f93e] succeeded in 0.13112432399066165s: 'hello siema'
I can also see my peresisted result inside result.db using great opensource sqlitebrowser.
There should be one entry inside celery_taskmeta table and if we click twice into result there should be hello siema inside that blob.
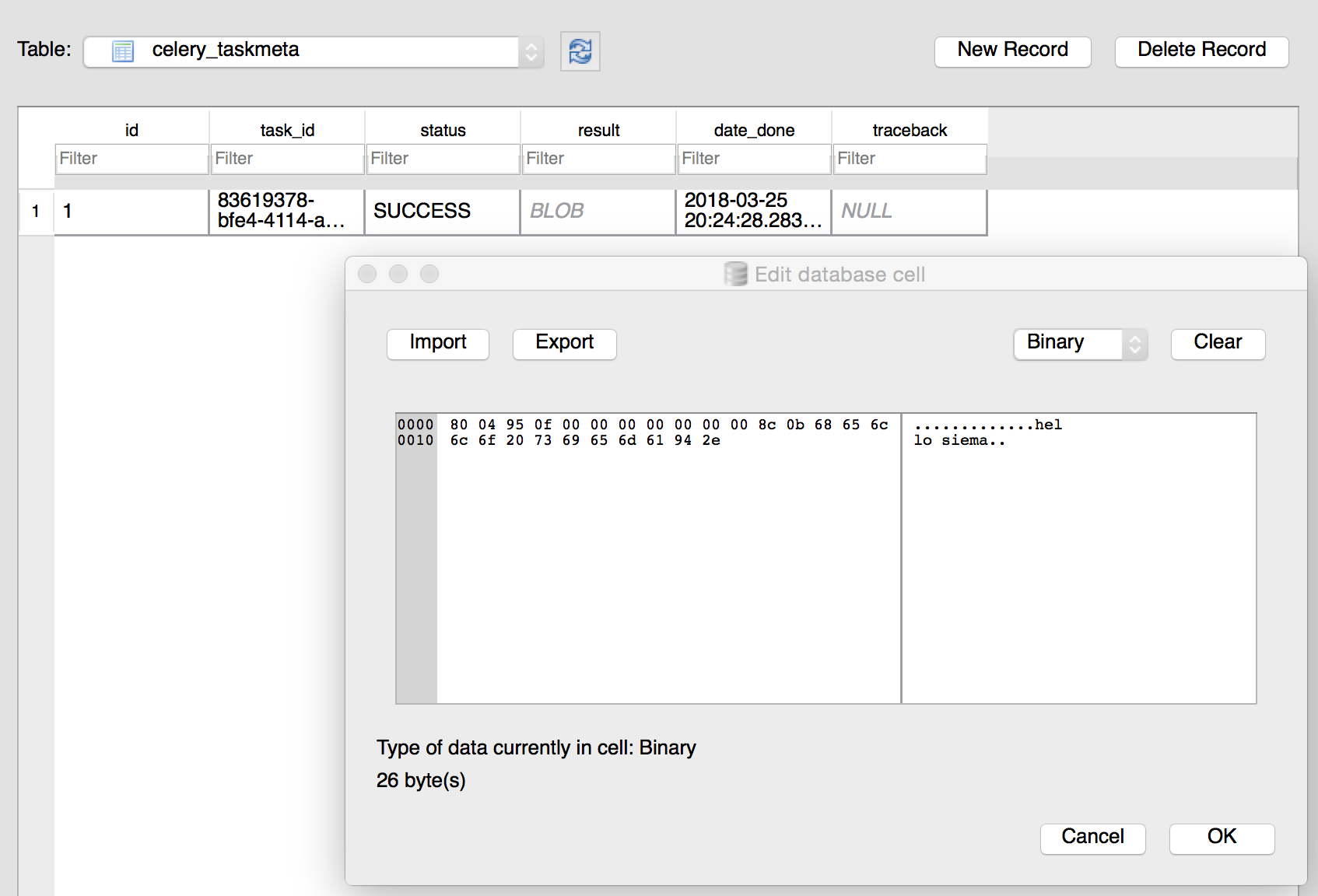 So that's it I can now leverage multiple files with workers and use them as I want to. Also I can run 2 workers in 2 terminals to see which one would pick task and how the tasks are distributed.
All the code from this celery example is available on github here.
So that's it I can now leverage multiple files with workers and use them as I want to. Also I can run 2 workers in 2 terminals to see which one would pick task and how the tasks are distributed.
All the code from this celery example is available on github here.
enjoy